|
Bioacoustic means study of acoustic characteristics and biological significance of sounds emitted by living organisms. Before discussing spectrograms, this page provides a brief explanation of how sound is represented digitally.
Sound consists of travelling waves of alternating compression and rarefaction of an elastic medium (e.g. air), generated by some vibrating object: for birds this object is the syrinx - organ of voice or song - situated, unlike the human larynx, at the lower end of the trachea and the junction of the two bronchi. Although variable in structure and complexity between groups of birds, it is generally a bony and cartilaginous chamber containing membranes which are activated by the passage of air from the lungs.(Bibliography 1) An electromechanical transducer (microphone) translates these waves into a continuous, time varying electric signal. Before analyzing this signal with a computer, it must be digitized by an analog-to-digital (A/D) converter . Fig. 1 explains how this process takes place:
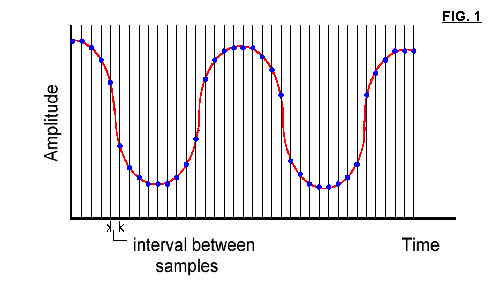
The number of waves (or cycles) per second is the signal frequency; the frequency unit is called Hertz (1 Hz = 1 cicle per second). In fig. 1 the red sinusoidal line represents a pure tone ( = constant frequency) signal. Each vertical thin line indicates the time when the A/D converter measures an instantaneous voltage amplitude value of the input signal. Blue points are the values measured ( sampled ) by the A/D converter. The digital representation of the signal thus consists of a sequence of numeric values that are the amplitude of the original waveform at evenly spaced points in time.
The precision with which the digitized signal represents the original input waveform depends on two parameters: the number of values sampled by the converter per second (= sampling rate) and the number of bits used to measure each amplitude value (=sample size). Fig. 2 shows the misleading results obtained with an inadequate sampling rate or sample size.
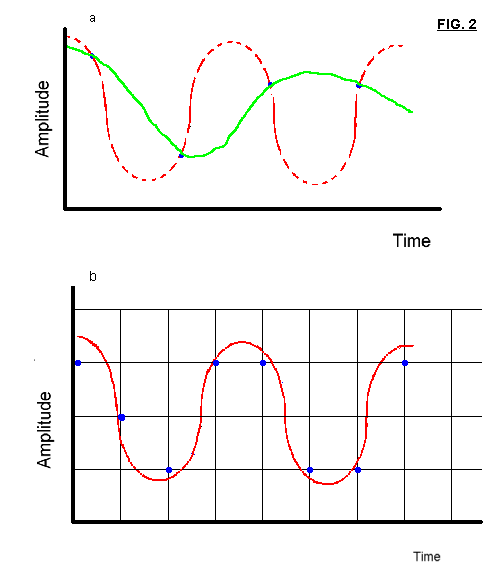
Fig 2a shows the effect of inadequate sample rate : the resulting digitized waveform (green line) portrays a sinusoid of lower frequency than the original input signal (red line); this phenomenon is called aliasing. In this case sampling frequency is approximately 1.3 times the signal frequency : a low rate! To avoid aliasing the sampling frequency must be at least two times the peak frequency of your signal.
Fig. 2b shows the errors obtained with a hypothetical 2-bit sample size, which can represent only 4 amplitude levels. The amplitude values for some samples (blue dots) are different from the true levels of the signal at the time the sample was taken. Increasing the sample size to 8 bits (= 256 levels) or to 16 bits (=65536 levels) avoids these errors.
A digitized sound signal can be depicted in two different forms, called time-domain and frequency-domain representations. In the time-domain the signal amplitude is plotted as a function of time, while in the frequency-domain the amplitude is represented as a function of frequency. In Fig. 3 the same sinusoidal signal is shown in both these forms .
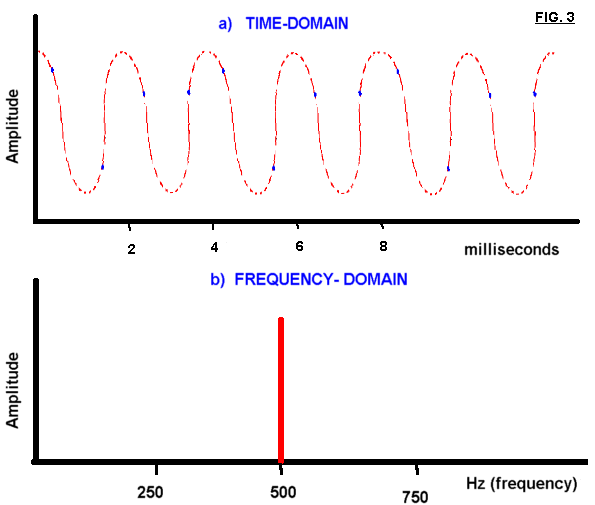
Fig. 3a is a time-domain representation of a pure sinusoidal signal with a frequency of 500 Hz. Fig. 3b is a correspondent frequency-domain plot.
The mathematical function that allows conversion between these two forms is the Discrete Fourier Transform (DFT) and the algorithm generally used to implement the DFT is the Fast Fourier Transform (FFT). The input of the FFT is a finite sequence of amplitude values of the signal sampled (digitized) at regular intervals. The output are values specifying the amplitudes associated to a sequence of frequency components, evenly spaced from zero Hz to half the sampling frequency. This output is also called power spectrum of the waveform or magnitude spectrum, because it contains information about the magnitude of each frequency component in the entire signal.
The sound signals depicted in Fig.1/2/3 are simple sinusoidal waves; therefore they are pure tones. But normally bird songs or calls are far more complex: the waveform is made by many different frequency components. The principle underlying DFT is that any complex sound can be broken down into a set of pure sinusoidal waves in much the way that any colored light can be broken down into basic colors of the visual spectrum. (Bibliography 2)
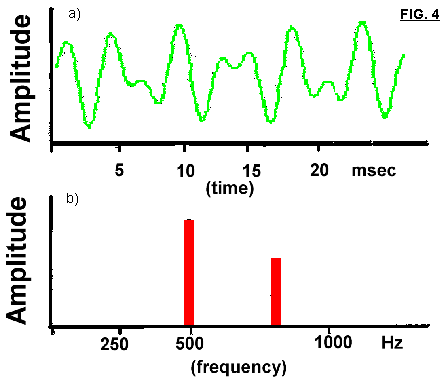
Fig. 4a shows a sound waveform consisting of two different frequencies (500 and 800 Hz) combined together. Fig. 4b is the correspondent magnitude spectrum, where we can find the two frequencies associated with their relative amplitudes.
Go to the next page for introducing the spectrograms. return to top
|